
Whether or not Twitter data is structured is relatively straightforward to assess, or is it? When we say Twitter data, we almost all typically presume the written text data of the users’ tweet. However, in the broader sense “twitter data” does include other data points such as the user, the times tweets are made, the location, images or links tagged etc. So presented broadly, “Twitter data” is more accurately described as semi-structured data because we have a mixture of structured data and unstructured data to observe; but the tweet text in and of itself is unstructured data. Lets dive into how we come to determine if twitter data is unstructured or structured data.
What is Structured Data?
Structured data is data that can easily be mapped to predefined fields of a table’s columns. It is usually stored in table format and you will often hear words like its relational which simply means it has a “key” such as a unique identifier that can easily be mapped to another table. A good example of structured data in Twitter data is the time a tweet was made. It’s a clear precise point and piece of data that can be easily mapped to a column such as “time” in a table. A great advantage of structured data is we can query it very easily. Typically this is done with a language called Structured Query Language or SQL for short. For example, if I wanted to find out how many users made a tweet between 10am and 11am I could do something like:
SELECT Users.UserId, Twitter.Tweet, Twitter.Time
FROM Twitter
INNER JOIN Users ON
Twitter.UserId=Users.UserId
WHERE Twitter.Time >=10am OR <=11am
What is Unstructured Data?
So you would probably describe unstructured data as data that will not fit or conform easily into a table and you couldn’t easily perform queries on. Unstructured data has its own internal structure and can include things like written text, audio, images etc. A lot of business interactions are unstructured think emails, blogs, social media content etc and over 80% of data generated is unstructured. Some of the biggest areas of machine learning analysis within the world of artificial intelligence today is Natural Language Processing and Computer Vision. These are deep learning specializations that allow us to understand and parse certain types of data to develop machine models with. Natural Language processing focuses on text and speech, think twitter, social media data and computer vision think Tesla, self-driving cars etc. Unpacking unstructured data can provide a lot of insight, being able to process it into a format that can be used to derive insight and decision making can be extremely powerful. One of my favourite applications is an area of NLP known as sentiment analysis which is opinion mining and trying to classify user sentiment as data, identify the patterns and derive insight. As an example, I can perform sentiment analysis on Twitter data. So if we wanted to analyse Trump’s tweet and look at the sentiment in the data against say fluctuations within the stock market, we might see a correlation between the two for example and develop a predictive model around that. Unstructured data is extremely powerful, there aren’t really limits to how creative you can get with being able to extract and use it for modelling. Unstructured data is typically stored in data lakes (enormous store of data in its raw original format until needed) or NOSQL for example, which can take the form of a graph or document database such as MongoDB.
What is Semi-structured Data?
Clearly, this leaves us somewhere in the middle of both. Essentially semi-structured data has a combination of structured data and unstructured data at play. What is distinct about unstructured data is it allows some sort of semantic tagging to understand/structure the data with. The key feature to look for when identifying semi-structured data is there is some sort of classification or tagging in its underlying characteristic. This is why it is not completely accurate to lump Twitter data as unstructured data but more accurately defining it as semi-structured data. Graphs are increasingly becoming a popular method of storing unstructured data with the likes of companies like Google, Facebook and Twitter due to the explosion in data volumes, frequent schema changes and more intelligent data activation needs. Graphs allow us to deal with the complexity of the data. Graphs allow us store relationships along with the data, allowing us to query these relationships and their properties by organising them into nodes with edges. Now with all this said, and given Twitter falls in the semi-structured to unstructured data type class, one could easily conclude its built on a graph database structure…but not so quickly!
What Type of Database Does Twitter Use?
Twitter actually started off using a MySQL relational database before introducing a more distributed form of this and then in 2010 introduced a fault-tolerant graph database called FlockDB that sits on the MySQL storage. The reality is, MySQL is still used; there are several layers and purposes for data storage/backups that are created. The current stack seems to be MySQL, then Snowflake as their unique identifier, then Hadoop for analytics and then Manhattan a distributed database system. So what’s so attractive about the MySQL solution? Well this may be easier to explain in a quick example. Primarily, graph databases support the concept of index free adjacency meaning every node can directly point to a neighbour. The driver behind the graph storage method means we are not confined to always linking everything in normalised relational data tables and end up with an unnecessary large volume of data to store, we can be more flexible in our approach. So imagine we have these two tables that explain the friendship of User “Alice” to other people at her university below.

Given the name “Alice” its much easier and faster for you to use table 2 to find all of Alice’s friends, right? Its also more efficient for the algorithm. However, social media platforms like Facebook still choose to use Memcache (distributed memory caching method to speed up dynamic database driven sites) which identifies the most active dataset for indexing a MySQL database as it is in-memory through key value store to access the data easily and efficiently. MySQL is a more mature platform that also provides additional benefits outside of indexing that they benefit from such replication, recovery e.t.c. That said, if constructed intelligently you can still preserve the principles of Graph organisation in a No-Graph situation like MySQL. MySQL is not only used by platforms like Twitter but Facebook and YouTube also employ its usage, as with Twitter this isn’t the only database layer in action, they will typically combine other NoSQL, Graph methodologies alongside it.
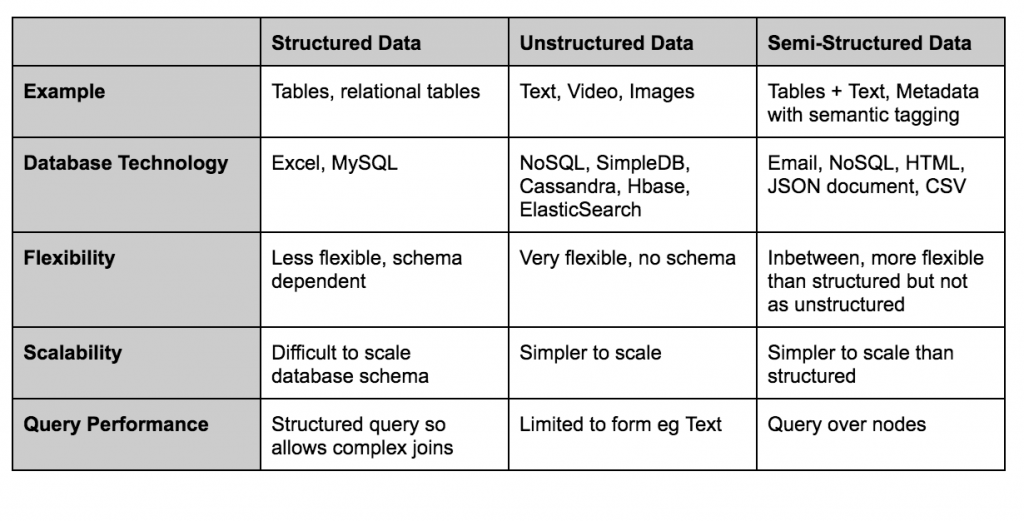
Summary – Types of Data At A Glance








Add Comment